Shaking Up VLMs: Comparing Transformers and Structured State Space Models for Vision & Language Modeling
Jan 1, 2024
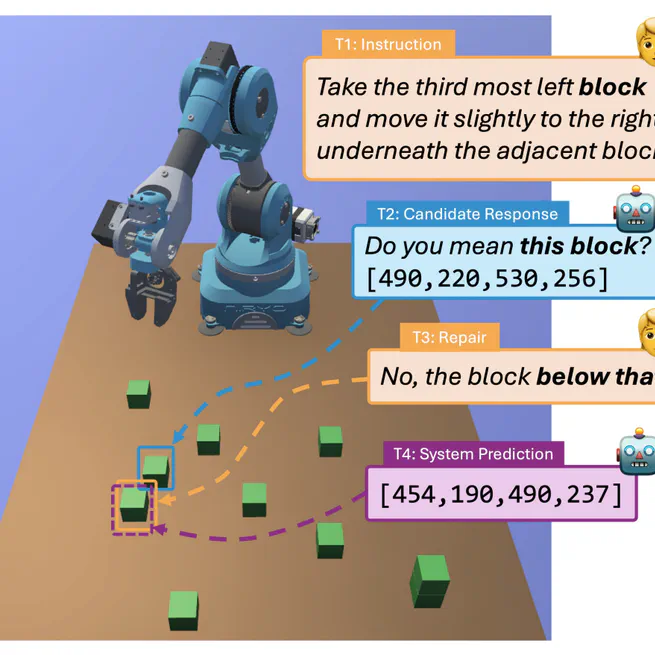
Repairs in a Block World: A New Benchmark for Handling User Corrections with Multi-Modal Language Models
Jan 1, 2024
PIXAR: Auto-Regressive Language Modeling in Pixel Space
Jan 1, 2024
Lost in Space: Probing Fine-grained Spatial Understanding in Vision and Language Resamplers
Jan 1, 2024
Investigating the Role of Instruction Variety and Task Difficulty in Robotic Manipulation Tasks
Jan 1, 2024
Human - Large Language Model Interaction: The dawn of a new era or the end of it all?
Jan 1, 2024

AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Jan 1, 2024

Multitask Multimodal Prompted Training for Interactive Embodied Task Completion
Jan 1, 2023
An Analysis of Visually Grounded Instructions in Embodied AI Tasks
Jan 1, 2023
'What are you referring to?' Evaluating the Ability of Multi-Modal Dialogue Models to Process Clarificational Exchanges
Jan 1, 2023